I was reviewing some code and it had these map references but they
were of the format:
mapName.THIS_KEY
mapName.ANOTHER_KEY
Then I googled and saw that:
"Finally, the dot operator and the bracket operator are somewhat
interchangeable. For example, ${user["firstName"]} could also be used
to retrieve the firstName property of the user object, just as
${commands.dir} could be used to fetch the value associated with the
"dir" key in the commands map."
REF: http://www.ibm.com/developerworks/java/library/j-jstl0211/index.html
I can see why, because it allows multi-dimensional maps to be
referenced like this:
mapName.ANOTHER_KEY.SOMEKEY_INSIDE_THAT_INSIDE_MAP
and won't go Boom! when the ANOTHER_KEY lookup returns nothing.
I still find it kinda icky. I think the dot expression should really
be used sparingly.
If you're doing lookups only one level deep, then it is so much easier
to understand when you do map lookups the same way you do it in normal
Java code.
Thursday, 29 November 2012
Thursday, 22 November 2012
"Print this page" functionality using jQuery - opening a print-friendly page
Certain pages on my current project have either a 'Print', or both
'Print' and 'Email' icons.
The implementation in the old system works like this:
- user clicks on Print icon, triggering a javascript request
- request includes the portlet Id and content Id as a parameter,
opening a new page
- the new page reads in the parameters and reloads the same contents
as the first page
- user can preview page and then print
I've reimplemented it using only jQuery, to make it as simple and
reusable as possible, and works like this:
- printable elements of the page either have a class or are enclosed
in a div with the class "printable"
- user clicks on Print icon, triggering a Javascript function which:
- loads a new page with print-friendly template, but with no content of its own
- on the new page, upon loading, Javascript runs to extract the
content with class "printable" from the parent window
- this content is then inserted into new page
- user can preview page and then print
The basic code is:
(add this to print page)
<script type='text/javascript'>
function printClick() {
window.open('print_template.html');
}
function getPrintContent (printSelector) {
// .clone() is required otherwise the content seems to be moved from
opening page to new page
var selections = $(printSelector).clone();
return selections;
}
$(function() {
// modify this to whatever we need to select the "Print" link.
$("li.print a").click(printClick);
});
</script>
(and on print page -- extract content from opener)
<script type='text/javascript'>
$(function() {
$('#main-content-wrapper').html( window.opener.getPrintContent('.printemail') );
});
</script>
I am inclined to replace the use of "printable" class and just enclose
all the print elements in one div and just get the contents from that
div. This is mainly due to having all our content managed in a CMS,
and if the producer does not include the "printable" class, then the
element won't get included on the print page.
'Print' and 'Email' icons.
The implementation in the old system works like this:
- user clicks on Print icon, triggering a javascript request
- request includes the portlet Id and content Id as a parameter,
opening a new page
- the new page reads in the parameters and reloads the same contents
as the first page
- user can preview page and then print
I've reimplemented it using only jQuery, to make it as simple and
reusable as possible, and works like this:
- printable elements of the page either have a class or are enclosed
in a div with the class "printable"
- user clicks on Print icon, triggering a Javascript function which:
- loads a new page with print-friendly template, but with no content of its own
- on the new page, upon loading, Javascript runs to extract the
content with class "printable" from the parent window
- this content is then inserted into new page
- user can preview page and then print
The basic code is:
(add this to print page)
<script type='text/javascript'>
function printClick() {
window.open('print_template.html');
}
function getPrintContent (printSelector) {
// .clone() is required otherwise the content seems to be moved from
opening page to new page
var selections = $(printSelector).clone();
return selections;
}
$(function() {
// modify this to whatever we need to select the "Print" link.
$("li.print a").click(printClick);
});
</script>
(and on print page -- extract content from opener)
<script type='text/javascript'>
$(function() {
$('#main-content-wrapper').html( window.opener.getPrintContent('.printemail') );
});
</script>
I am inclined to replace the use of "printable" class and just enclose
all the print elements in one div and just get the contents from that
div. This is mainly due to having all our content managed in a CMS,
and if the producer does not include the "printable" class, then the
element won't get included on the print page.
Friday, 9 November 2012
Could you please introduce yourself with more bullshit per syllable?
Anyone who starts off their comment in this manner: "As a UK based
international entrepreneur trying to bring change and transformation
with new internet architectures, technology and business models for
digital eco-systems..." is a total wanker. #rulesoftheinternet
And when you talk about looking for your "Bit Torrent login details" -
you are also a moron.
http://techcrunch.com/2012/11/07/reserving-judgements-is-a-matter-of-infinite-hope
international entrepreneur trying to bring change and transformation
with new internet architectures, technology and business models for
digital eco-systems..." is a total wanker. #rulesoftheinternet
And when you talk about looking for your "Bit Torrent login details" -
you are also a moron.
http://techcrunch.com/2012/11/07/reserving-judgements-is-a-matter-of-infinite-hope
Wednesday, 31 October 2012
Tabs and Me
Principal Skinner: Answers! Answers! -- "Separate Vocations", Simpsons Season 3
That's how having dozens of tabs open at the same time makes me feel. Kinda.
Yah. Sucks to be me.
Saturday, 13 October 2012
Git-Svn - a noob's journey, Week 1-2
I've wanted to try out Git for quite a while. Maybe it's just me, the
type of person who wants to know every frigging thing about something
before actually going ahead and doing it, but I've been trying to get
my head around the whole DVCS thing, and still not completely happy
with what I knew. So I kept on reading, mostly blog posts because the
official sources were not that readable, frankly. Problem with blog
posts is that obviously they don't cover everything, and seemed to
raise a lot of corner cases that I didn't feel I understood enough.
That and we used Subversion for our source control at work. So I
didn't see the point. Then I found out about GIt-Svn, which seems to
me the best of both worlds, at least in theory. These are just some
observations and maybe tips for people who want to give git-svn a try.
* OMG. I LOVE the stash functionality. The ability to move your
current working changes into temporary storage, without the
"commitment" of making branches is much welcome.
* git svn rebase means more frequent updates to your working copy,
minimising the chance your changes stray too far from what everyone is
doing.
* I think in the long term, I just need to think about branches in a
new way, since 1. branches can be local, so no one sees the
embarrassing things you're doing; and 2. working in branches means you
can get the latest and greatest code from svn synced to master without
having it cause you any worry about conflicts, etc.
* I had the mistaken idea that if you were using git-svn, that you
couldn't merge from branches. This wasn't the complete picture. Turns
out it's merging between SVN branches in your git repository that you
shouldn't do (see:
http://stackoverflow.com/questions/2693771/git-svn-merge-2-svn-branches)
If you just make a local branch, don't create it remotely in SVN, do
your changes there instead of on "master" (equivalent to svn trunk),
then merge changes back to trunk - that's completely okay.
* Somehow, I lost my changes, even after stashing them. If you make a
stash, don't pop them (ie, apply them and remove from the saved
stashes). I was doing an svn rebase, so stashed the working changes
first. Then the rebase got a conflict, which I then tried to merge. My
merge didn't seem to work, and I saw a post of a similar problem that
said to just do "git rebase --skip". Then my stash wasn't around
anymore! This took me a couple of tries to sort out. Also learned
about "git fsck", which probably would have helped me instead of me
having to manually recreate my changes.
* Don't forget that any commits you make are only local. No one will
see them until you do "git svn dcommit". I knew this would happen to
me eventually. I broke the build doing this, after sending out an
email saying "Yeah, I've fixed the build." then going home. I can also
very easily imagine this happening at a great scale if we ever adopt
it at our workplace.
Please keep in mind that the information here may or may not be
entirely correct. Corrections, comments and advise from more
experienced users are welcome.
TODO: update with list of helpful URLs for git-svn
type of person who wants to know every frigging thing about something
before actually going ahead and doing it, but I've been trying to get
my head around the whole DVCS thing, and still not completely happy
with what I knew. So I kept on reading, mostly blog posts because the
official sources were not that readable, frankly. Problem with blog
posts is that obviously they don't cover everything, and seemed to
raise a lot of corner cases that I didn't feel I understood enough.
That and we used Subversion for our source control at work. So I
didn't see the point. Then I found out about GIt-Svn, which seems to
me the best of both worlds, at least in theory. These are just some
observations and maybe tips for people who want to give git-svn a try.
* OMG. I LOVE the stash functionality. The ability to move your
current working changes into temporary storage, without the
"commitment" of making branches is much welcome.
* git svn rebase means more frequent updates to your working copy,
minimising the chance your changes stray too far from what everyone is
doing.
* I think in the long term, I just need to think about branches in a
new way, since 1. branches can be local, so no one sees the
embarrassing things you're doing; and 2. working in branches means you
can get the latest and greatest code from svn synced to master without
having it cause you any worry about conflicts, etc.
* I had the mistaken idea that if you were using git-svn, that you
couldn't merge from branches. This wasn't the complete picture. Turns
out it's merging between SVN branches in your git repository that you
shouldn't do (see:
http://stackoverflow.com/questions/2693771/git-svn-merge-2-svn-branches)
If you just make a local branch, don't create it remotely in SVN, do
your changes there instead of on "master" (equivalent to svn trunk),
then merge changes back to trunk - that's completely okay.
* Somehow, I lost my changes, even after stashing them. If you make a
stash, don't pop them (ie, apply them and remove from the saved
stashes). I was doing an svn rebase, so stashed the working changes
first. Then the rebase got a conflict, which I then tried to merge. My
merge didn't seem to work, and I saw a post of a similar problem that
said to just do "git rebase --skip". Then my stash wasn't around
anymore! This took me a couple of tries to sort out. Also learned
about "git fsck", which probably would have helped me instead of me
having to manually recreate my changes.
* Don't forget that any commits you make are only local. No one will
see them until you do "git svn dcommit". I knew this would happen to
me eventually. I broke the build doing this, after sending out an
email saying "Yeah, I've fixed the build." then going home. I can also
very easily imagine this happening at a great scale if we ever adopt
it at our workplace.
Please keep in mind that the information here may or may not be
entirely correct. Corrections, comments and advise from more
experienced users are welcome.
TODO: update with list of helpful URLs for git-svn
Friday, 12 October 2012
Say my name, say my name
Oh boy, this post about "Taking on an English name" hits the spot. Having been given a slightly non-standard name by my parents, I've had my name mangled quite a number of ways. But I understand why it gets mangled. It's different, it's unusual! I geddit. And a lot of people are *not* used to reading phonetically, unaware of other names because they don't friggin read enough or know about the world, or just plain can't spell even if the letters are in front of them.
But here's the thing: instead of giving up, and getting a new name, why not try TEACHING people how to say your name? Educate them, and teach them to make new sounds with phonemes. Teach them how to make sounds they never thought could be done with letter combinations!
In the end, for me, it's all about respect. Respecting other people's cultures to learn their name. Pay attention to how they say it, because "correct" is always defined by the owner of the name. (even those normal-but-misspelt names like Jazzmyn)
To some it might be trivial, but to me if you can't be arsed getting someone's name right, what more when it comes to other things that actually require a bit more effort?
Your name matters. The more you teach people, the easier it becomes both for that person and other people who have "strange" names. Do it. Do it for little Zbignew and Raghavendra.
But here's the thing: instead of giving up, and getting a new name, why not try TEACHING people how to say your name? Educate them, and teach them to make new sounds with phonemes. Teach them how to make sounds they never thought could be done with letter combinations!
In the end, for me, it's all about respect. Respecting other people's cultures to learn their name. Pay attention to how they say it, because "correct" is always defined by the owner of the name. (even those normal-but-misspelt names like Jazzmyn)
To some it might be trivial, but to me if you can't be arsed getting someone's name right, what more when it comes to other things that actually require a bit more effort?
Your name matters. The more you teach people, the easier it becomes both for that person and other people who have "strange" names. Do it. Do it for little Zbignew and Raghavendra.
Monday, 24 September 2012
IntelliJ IDEA has a built in Regex Tester

so I don't know how long it's been around. I know it wasn't there the
last time I worked on a lot of Regex Java code.
A built-in Regex tester within the editing window of IntelliJ IDEA. So
you write the regex in your code, you can test it right there!
Friday, 21 September 2012
Corporate proxies blocking spam sites
Interesting. Clicked on a link in an email I got and got this message
instead in my browser:
"This Page Cannot Be Displayed
Based on your corporate access policies, this web site (URL redacted
by me) has been blocked because it has been determined by Web
Reputation Filters to be a security threat to your computer or the
corporate network. This web site has been associated with
malware/spyware.
Threat Type: spam
Threat Reason: Domain has unusually high traffic volume for a very
recent registration. IP/domain is a spam source.
If you have questions, please contact your corporate network
administrator and provide the codes shown below.
Notification codes: (1, MALWARE, spam, Domain has unusually high
traffic volume for a very recent registration. IP/domain is a spam
source., BLOCK-MALWARE, 0x476c8b41, 1348186815.265,
QAAAAAAAAAAAAAAAJf8ACP8AAAD/AAAAAAAAAAAAAAA=, URL redacted by me)"
instead in my browser:
"This Page Cannot Be Displayed
Based on your corporate access policies, this web site (URL redacted
by me) has been blocked because it has been determined by Web
Reputation Filters to be a security threat to your computer or the
corporate network. This web site has been associated with
malware/spyware.
Threat Type: spam
Threat Reason: Domain has unusually high traffic volume for a very
recent registration. IP/domain is a spam source.
If you have questions, please contact your corporate network
administrator and provide the codes shown below.
Notification codes: (1, MALWARE, spam, Domain has unusually high
traffic volume for a very recent registration. IP/domain is a spam
source., BLOCK-MALWARE, 0x476c8b41, 1348186815.265,
QAAAAAAAAAAAAAAAJf8ACP8AAAD/AAAAAAAAAAAAAAA=, URL redacted by me)"
Wednesday, 29 August 2012
Renaming files in TortoiseHg
TortoiseHg, so things are still a bit unclear for me. I know, I know,
I should be reading http://hginit.com all the way through to get a
good grounding in Mercurial, but it seems to be okay so far.
I'm testing out Mercurial on a little project I have to restructure a
project to use Maven instead of Ant, so there's inevitably some moving
of directories required.
But how do you move a file in Mercurial?
This is the annoying thing, they never use that word "move". They call
it "rename". I get it, Mercurial only cares about files, but for the
sake of real-world users who still use the word "move", there could be
a bit more guidance on this, IMHO.
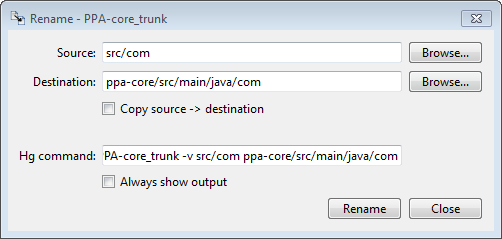
Anyway, how to move a directory in TortoiseHg? You go to the parent
directory using Explorer, then you right-click and select "Rename".
Then you will get a dialog box where you select the location you will
place it in. By default, it will show the existing name (ie,
"src/com") in both the Source and Destination text fields. Now for the
Destination field, click on the corresponding "Browse" button and
select the new location where you will place the directory.
IMPORTANT: Make sure the name of the directory is also in the
destination field, as the contents will be moved to whatever location
is specified in Destination.
There is a checkbox with "Copy source -> destination" - what is this for?
It turns out this is just a way for the Mercurial "copy" command being
included in the Rename dialog. It's a bit of a confusing hack, in my
opinion.
It's annoying that this is not discussed in the docos I've seen for TortoiseHg.
Found out from here:
https://bitbucket.org/tortoisehg/hgtk/issue/1124/support-for-copy-command
If you tick the checkbox, it means Mercurial will copy the files, and
not move them. You'll end up with two copies, which might not be what
you want to do.
TOP TIP:
This is not the best way to move files or directories around. The best
way is to just move them, and then go to the top of the directory,
then right-click TortoiseHg to "Guess Renames"
Wednesday, 1 August 2012
Bloody hell. Simple WSRP demo works on Liferay Enterprise, but not on Liferay Community Edition
Spent a few days trying to get a simple "Hello World" portlet working
via WSRP, using 2 instances of Liferay running on my machine. Tried
6.0 CE. Didn't work. Saw a bug related to "Adding a WSRP Consumer",
JIRA said it was fixed in Liferay 6.1. Tried it on Liferay 6.1 CE as
consumer pointing to Liferay 6.0CE as producer: didn't work.
After a few days trying things like getting specific version of the
WSRP plugin to match the version of Liferay, multiple restarts, I've
now downloaded the Enterprise version of Liferay 6.0, matching it to
what we currently use in production.
I then set up a simple portlet as WSRP producer and then WSRP consumer
on the other Liferay instance: works perfectly.
Is this what they mean by "value-add"?
via WSRP, using 2 instances of Liferay running on my machine. Tried
6.0 CE. Didn't work. Saw a bug related to "Adding a WSRP Consumer",
JIRA said it was fixed in Liferay 6.1. Tried it on Liferay 6.1 CE as
consumer pointing to Liferay 6.0CE as producer: didn't work.
After a few days trying things like getting specific version of the
WSRP plugin to match the version of Liferay, multiple restarts, I've
now downloaded the Enterprise version of Liferay 6.0, matching it to
what we currently use in production.
I then set up a simple portlet as WSRP producer and then WSRP consumer
on the other Liferay instance: works perfectly.
Is this what they mean by "value-add"?
Wednesday, 25 July 2012
Running multiple instances of Tomcat on different ports on same server
I wanted to run two instances of Tomcat on different ports on my
workstation, and this is what I did.
Modify these values in /[TOMCAT INSTALL DIRECTORY]/conf/server.xml.
In this example we are using "7" to replace the "8" in the port numbers
ie, 2nd tomcat to run on port 7070 instead of 8080, shutdown port is
7005, AJP connector port is 7009
<!-- DEFAULT VALUE: 8005 -->
<Server port="7005" shutdown="SHUTDOWN">
<!-- DEFAULT VALUE: 8080 -->
<Connector port="7070" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<!-- DEFAULT VALUE: 8009 -->
<Connector port="7009" protocol="AJP/1.3" redirectPort="8443"
URIEncoding="UTF-8" />
workstation, and this is what I did.
Modify these values in /[TOMCAT INSTALL DIRECTORY]/conf/server.xml.
In this example we are using "7" to replace the "8" in the port numbers
ie, 2nd tomcat to run on port 7070 instead of 8080, shutdown port is
7005, AJP connector port is 7009
<!-- DEFAULT VALUE: 8005 -->
<Server port="7005" shutdown="SHUTDOWN">
<!-- DEFAULT VALUE: 8080 -->
<Connector port="7070" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<!-- DEFAULT VALUE: 8009 -->
<Connector port="7009" protocol="AJP/1.3" redirectPort="8443"
URIEncoding="UTF-8" />
Thursday, 5 July 2012
Adventures in legacy code: given a Map-based class, what do you think a method called getKey() should do?
Looking at some legacy code for a system that we're taking back from a
vendor. (Company has all these projects in-housing systems that used
to be outsourced) Rehost, port or rewrite?
Okay, so they created a class BundleMap that extends HashMap, and the
genius who wrote it added this incredible WTF "improvement":
/**
* Check if the key is present in the resource bundle
*
* @param key
* @return true if key is present
*/
public Boolean getKey(Object key) {
logger.debug("Returning value for key [" + key + "]");
if (super.containsKey(key)) {
return true;
}
return false;
}
AGAIN - WTF???
you already have a perfectly good method called containsKey() in
HashMap -- whatever the hell possessed you to rename it as getKey()??
vendor. (Company has all these projects in-housing systems that used
to be outsourced) Rehost, port or rewrite?
Okay, so they created a class BundleMap that extends HashMap, and the
genius who wrote it added this incredible WTF "improvement":
/**
* Check if the key is present in the resource bundle
*
* @param key
* @return true if key is present
*/
public Boolean getKey(Object key) {
logger.debug("Returning value for key [" + key + "]");
if (super.containsKey(key)) {
return true;
}
return false;
}
AGAIN - WTF???
you already have a perfectly good method called containsKey() in
HashMap -- whatever the hell possessed you to rename it as getKey()??
Thursday, 3 May 2012
Maven dependency resolution problems caused by child module having a different parent version from top level parent pom.xml
The moral of the story is: When working on a multi-module project,
remember to update ALL pom.xml files, not just one version. Update
from the top-level often.
I'm working on a multi-module Maven project, and Bamboo (our
continuous integration server) is set up so that whenever a release is
done, the version number is incremented.
Now we have most of our dependencies set up in the parent-level
pom.xml. One of them is a client jar to our web services backend. Call
it services-client.jar
I've just spent an afternoon trying to sort out this very confusing
situation where I'd already updated the dependency in our pom.xml to
services-client-19.jar, but whenever I did a build, I would also get
services-client-17.jar.
I thought at first that it was an IDE problem, IntelliJ getting
confused with its caches, so I tried all sorts of fixes at that level
- cleared cache, recreated project file, reimport all Maven projects,
manually delete jars in settings - nothing worked.
I then went to command-line, removed all versions of
services-client*.jar from local repo, then did a build. I grep'd
through all my pom.xml files, and I saw that I only had one reference
to services-client, it was in top-level pom.xml and and it was version
19.
$ find . -name "pom.*" -exec grep -i "0.1203." {} /dev/null \;
./domain/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./extension/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./front-end/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./pom.xml: <version>0.1203.0.138-SNAPSHOT</version>
While this was using services-client-19.jar:
./pom.xml: <version>0.1203.0.138-SNAPSHOT</version>
The child-level modules were pointing to an older parent pom file, one
that Bamboo already installed to our company repository.
The parent version used in the child modules:
./domain/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
Was using services-client-17.jar
So whenever did "mvn clean install" the project from the
parent-level, Maven was following this sequence when resolving the
dependencies:
1) Maven goes to child modules and builds
2) In /domain/pom.xml - it sees the reference to older parent pom,
fetches from repository, starts to resolve dependencies, fetches older
services client - services-client-17.jar.
3) services-client-17.jar gets installed in local repo
4) During build, code that uses services-client-19.jar code fails
compilation because that jar never actually gets installed until Maven
gets to the top most pom.xml
I haven't verified this with the Maven mailing list yet, this is just
my interpretation of what the problems have been.
The moral of the story is: When working on a multi-module project,
remember to update ALL pom.xml files, not just one version. Update
from the top-level often.
I have updated at the top level and the parent versions are now
consistent - 0.1203.0.140 all the way.
$ find . -name "pom.*" -exec grep -i "0.1203." {} /dev/null \;
./domain/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./extension/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./front-end/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
remember to update ALL pom.xml files, not just one version. Update
from the top-level often.
I'm working on a multi-module Maven project, and Bamboo (our
continuous integration server) is set up so that whenever a release is
done, the version number is incremented.
Now we have most of our dependencies set up in the parent-level
pom.xml. One of them is a client jar to our web services backend. Call
it services-client.jar
I've just spent an afternoon trying to sort out this very confusing
situation where I'd already updated the dependency in our pom.xml to
services-client-19.jar, but whenever I did a build, I would also get
services-client-17.jar.
I thought at first that it was an IDE problem, IntelliJ getting
confused with its caches, so I tried all sorts of fixes at that level
- cleared cache, recreated project file, reimport all Maven projects,
manually delete jars in settings - nothing worked.
I then went to command-line, removed all versions of
services-client*.jar from local repo, then did a build. I grep'd
through all my pom.xml files, and I saw that I only had one reference
to services-client, it was in top-level pom.xml and and it was version
19.
$ find . -name "pom.*" -exec grep -i "0.1203." {} /dev/null \;
./domain/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./extension/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./front-end/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
./pom.xml: <version>0.1203.0.138-SNAPSHOT</version>
While this was using services-client-19.jar:
./pom.xml: <version>0.1203.0.138-SNAPSHOT</version>
The child-level modules were pointing to an older parent pom file, one
that Bamboo already installed to our company repository.
The parent version used in the child modules:
./domain/pom.xml: <version>0.1203.0.134-SNAPSHOT</version>
Was using services-client-17.jar
So whenever did "mvn clean install" the project from the
parent-level, Maven was following this sequence when resolving the
dependencies:
1) Maven goes to child modules and builds
2) In /domain/pom.xml - it sees the reference to older parent pom,
fetches from repository, starts to resolve dependencies, fetches older
services client - services-client-17.jar.
3) services-client-17.jar gets installed in local repo
4) During build, code that uses services-client-19.jar code fails
compilation because that jar never actually gets installed until Maven
gets to the top most pom.xml
I haven't verified this with the Maven mailing list yet, this is just
my interpretation of what the problems have been.
The moral of the story is: When working on a multi-module project,
remember to update ALL pom.xml files, not just one version. Update
from the top-level often.
I have updated at the top level and the parent versions are now
consistent - 0.1203.0.140 all the way.
$ find . -name "pom.*" -exec grep -i "0.1203." {} /dev/null \;
./domain/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./extension/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./front-end/pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
./pom.xml: <version>0.1203.0.140-SNAPSHOT</version>
Wednesday, 2 May 2012
Dear Ticketmaster Australia: if a gig is sold out, just fucking tell me. I can handle it.
What I can't handle is being treated like an idiot and having my time wasted.
The fact that searching is allowed would naturally lead any user to
think that there is something to be found. But in this case, widening
my search to "Best Available" and "Any Price" still returns nothing!
If that's the case, why allow searches at all?
Instead of wasting everyone's time letting them search for tickets
that do not exist, just mention it upfront on the site if tickets have
sold out already. Don't waste my goddamn time!
What were your marketing fuckwits thinking? "Oh, maybe they'll stay
around longer on the site and buy tickets to something else!"
That's not how it works, assholes.
We just get pissed off and tell everyone your website is a piece of shit.
Unfortunately, consumers don't have any options as you and Ticketek
have the big events pretty much between yourselves.
Fuck. This.
The fact that searching is allowed would naturally lead any user to
think that there is something to be found. But in this case, widening
my search to "Best Available" and "Any Price" still returns nothing!
If that's the case, why allow searches at all?
Instead of wasting everyone's time letting them search for tickets
that do not exist, just mention it upfront on the site if tickets have
sold out already. Don't waste my goddamn time!
What were your marketing fuckwits thinking? "Oh, maybe they'll stay
around longer on the site and buy tickets to something else!"
That's not how it works, assholes.
We just get pissed off and tell everyone your website is a piece of shit.
Unfortunately, consumers don't have any options as you and Ticketek
have the big events pretty much between yourselves.
Fuck. This.
Friday, 13 April 2012
The cat food saga: the dry and the raw
I used to feed my 2 cats dry because my vet said so. All the places
I've been to - RSPCA, animal hospital, vets - sold mostly dry food
like Hills Science so I figured that was accepted good practice. Main
complaint I would have was the stink of their poo. One of the cats has
always been fanatical about covering up his offerings, but it still
had a strong smell despite being buried in the litter. In the mornings
my wife would always wake me up way earlier than I'd like to make me
clean up the litter boxes.
I've been to - RSPCA, animal hospital, vets - sold mostly dry food
like Hills Science so I figured that was accepted good practice. Main
complaint I would have was the stink of their poo. One of the cats has
always been fanatical about covering up his offerings, but it still
had a strong smell despite being buried in the litter. In the mornings
my wife would always wake me up way earlier than I'd like to make me
clean up the litter boxes.
Then a recent spell of cat gastro made me change their diet to mainly
raw meat, and it's completely all for the better. In Australia, wild
kangaroo meat is commonly sold as raw pet food. Kangaroo meat is very
lean, as kangaroos are not farmed animals. It's all from the wild.
Now i'm not 100% sure if it was the change to raw meat or if they were
already getting better. The smell is gone in the mornings. The stench
of the litter boxes don't fill up the house. It's possible it was just
something in that particular dry food didn't agree with them, but I
wasn't prepared to go and try out umpteen kinds of dry food to test
that theory.
Another impact of this is that they're using the litter box way more
to urinate, and it was starting to get expensive with the clumping
litter, but I've started trying out crystal litter which seems way
better and less expensive at dealing with cat wee. From the number of
times they urinate,I would say they now consume a lot more water
because of the wet food diet.
The transition to raw food was actually pretty uneventful. While
dealing with the gastro issues I did a timeout of 24 hrs on feeding
them, and this gave us a break on the cleanup and made them very
hungry and pretty receptive to ANYTHING that I gave them. They
finished their first bowl of raw meat very quickly! One of them was a
bit reluctant so for a few days I gave him his own mix with raw meat
and dry food.
I've started using canned cat food as backup, in cases where I'm out
of raw food or it hasn't thawed out yet. I've found this more
agreeable with them than switching back to dry food, or mixing wet and
dry in the same bowl. They still seem to be sensitive with changes to
diet, so I've just stuck to some canned brands that they like. I still
have some leftover Felidae, so the dry food remains as a last resort
or on the few times that I can't feed them myself.
Monday, 13 February 2012
Mystical spam message of the day
Found some truly mystical spam in my inbox today:
The coach with six horses was waiting at the porch.
Suggestion area: Barge in Now
Wholeheartedly your, Neiford Brandkamer.
Friday, 13 January 2012
Q: What is a blog?
Q on Yammer:
"now what about the question - is an online journal the same as blog?
although technically a blog is a weblog, blogs have grown into a
public domain where people discuss and banter over a certain topic or
discussion raised by the blogger. an online journal on the other hand
could be a dear diary or a "whate happened to me today". any thoughts
on this?"
A:
a blog is a blog
you can use it to share
or you can use it to care
you can use it to joke
or you can use it to poke
you can talk to other people
or stay alone in your steeple
its just a way to go 'bla bla bla'
and the only difference is
WHY you go 'bla bla bla'
(apologies to Dr Seuss)
Wednesday, 11 January 2012
Reintegration merge in SVN using TortoiseSvn
Currently doing some reintegration merges in SVN, and one thing
tripped me up. I forgot to commit the mergeinfo file that got created
during the merge!! This would have meant that SVN would have no
knowledge that a branch was already reintegrated back into trunk (or
another branch).
tripped me up. I forgot to commit the mergeinfo file that got created
during the merge!! This would have meant that SVN would have no
knowledge that a branch was already reintegrated back into trunk (or
another branch).
The process using TortoiseSVN would be:
For example, where we are merging big_branch_1 into trunk
1. Checkout trunk into working directory and go into this directory in Explorer
2. Using TortoiseSvn right-click and select TortoiseSvn --> Merge
3. On the Merge dialog box, select "Reintegrate a branch" radio
button, click Next
4. Under "Tree merge", and under "From URL" select the branch we want
to reintegrate, then click on Next.
5. Under "Merge options", you can select options such as ignoring or
comparing whitespace differences, etc.
I normally click on "Test merge" so it can go through a test of the
merge and show in advance any potential conflicts. (I haven't seen
any, but I think that's what it does)
7. Click on "Merge", and fix any conflicts that come up.
6. After that's done, do a commit, and put in an appropriate message
to indicate what you've done
7. NOTE 1: During the commit, make sure "Show unversioned files"
checkbox is ticked
NOTE 2: There will be an additional, unversioned change listed in the
commit list. At first I thought it was a new file, but it's actually
an updated SVN property.
The svn:mergeinfo property make sure you commit this change,
otherwise, SVN doesn't know that a branch has been reintegrated.
If you leave out this file from a commit, all that SVN knows is that
you put in a bunch of changes to a number of files.
In one earlier merge, I rolled back the "file". So I just went back
into that directory, ran through the merge again, and committed the
updated svn:mergeinfo.
There shouldn't be any other changes to commit since the changed files
have already committed. I only did this so that svn:mergeinfo was up
to date.
Some information in this post may be incorrect as I've never had to do
these types of merges before. I'll update them once I've read up more
on this.
Further reading:
http://durak.org/sean/pubs/software/version-control-with-subversion-1.6/svn.branchmerge.basicmerging.html
http://www.collab.net/community/subversion/articles/merge-info.html
Subscribe to:
Comments (Atom)